编写 brainfuck 解释器
使用 Node 编写 BF 解释器

代码
import fs from 'node:fs/promises';
import { Code } from './opcode.mjs';
import {Interpreter} from "./Interpreter.mjs";
const args = process.argv;
const target = args[2];
const file = await fs.readFile(target);
let code = Code.shared.from(file);
const interpreter = new Interpreter();
interpreter.run(code);import fs from 'node:fs';
import { stdin, stdout } from 'node:process';
import {readBytes} from "./util.mjs";
export const SHR = 0x3E; // > 的 charCode
export const SHL = 0x3C; // <
export const ADD = 0x2B; // +
export const SUB = 0x2D; // -
export const PUTCHAR = 0x2E; // .
export const GETCHAR = 0x2C; // ,
export const LB = 0x5B; // [
export const RB = 0x5D; // ]
export class Code {
instrs = []
jtable = new Map()
static shared = new Code();
constructor() {
}
from(data) {
const dict = new Set([
SHR,
SHL,
ADD,
SUB,
PUTCHAR,
GETCHAR,
LB,
RB,
]);
this.instrs = data.filter(code => {
if (!dict.has(code)) {
// 跳过不支持的操作服或空格
return false;
}
return true;
});
const stack = []
for (let i=0; i<this.instrs.length; i++) {
const code = this.instrs[i];
if (code === LB) {
stack.push(i);
}
if (code === RB) {
let j = stack.pop();
this.jtable.set(i, j);
this.jtable.set(j, i);
}
}
return this;
}
}import {stdin, stdout} from "node:process";
import {readBytes} from "./util.mjs";
import {ADD, GETCHAR, LB, PUTCHAR, RB, SHL, SHR, SUB} from "./opcode.mjs";
export class Interpreter {
stack = [0]
constructor() {
}
run(code) {
const codeLen = code.instrs.length;
let programCount = 0;
let stackPointer = 0;
while (true) {
if (programCount >= codeLen) { // 代码已结束
break;
}
const c = code.instrs[programCount] // 过滤后的代码数组
switch (c) {
case SHR:
stackPointer += 1;
if (stackPointer === this.stack.length) { // 纸带不够了
this.stack.push(0);
}
break;
case SHL:
if (stackPointer !== 0) {
stackPointer -= 1;
}
break;
case ADD:
this.stack[stackPointer] = (this.stack[stackPointer] + 1) % 256;
break;
case SUB:
let tmp = this.stack[stackPointer] -1;
this.stack[stackPointer] = tmp < 0 ? tmp + 256 : tmp;
break;
case PUTCHAR:
stdout.write(Buffer.from([this.stack[stackPointer]]), 'utf-8');
break;
case GETCHAR:
const buf = readBytes(stdin.fd, 1);
this.stack[stackPointer] = buf[0];
break;
case LB:
if (this.stack[stackPointer] === 0x00) {
programCount = code.jtable.get(programCount);
}
break;
case RB:
if (this.stack[stackPointer] !== 0x00) {
programCount = code.jtable.get(programCount);
}
break;
default:
// never
}
// console.log(String.fromCharCode(c), this.stack);
programCount += 1; // 读入下一个指令
}
}
}import fs from "node:fs";
export const readBytes = (fd, count) => {
const buffer = Buffer.allocUnsafe(count);
for (let i = 0; i < count;) {
let result = 0;
try {
result = fs.readSync(fd, buffer, i, count - i);
} catch (error) {
if (error.code === 'EAGAIN') { // when there is nothing to read at the current time (Unix)
//TODO: it is good to slow down loop here or do other tasks in meantime, e.g. async sleep
continue;
}
throw error;
}
if (result === 0) {
throw new Error('Input stream reading error.'); // consider to use your own solution on this case
}
i += result;
}
return buffer;
};util.mjs 是从命令行读入用户输入的函数,在 brainfuck 中,一次只能处理长度为 1 的输入,所以我们在后面使用该函数时,count 参数传 1。
在 opcode.mjs 中,我们使用常量的方式,定义了 8 个 BF 中支持的操作,由于以 readFile 读入时,每个操作符都被转成二进制的数组,每一位的值刚好是其 chartCode 的值,所以我们将其 charCode 作为常量的值。
由于 BF 中的 [, ] 可能会进行代码跳转,类似于括号匹配的问题,所以我们在预处理代码时使用栈处理出一个哈希表,方便代码执行时,进行快速跳转。
代码的执行,我们使用一个无限循环,有一个 programCount 执行代码执行的位置,特别地,当它执行代码的最后时,我们跳出循环表示代码执行结束。
还有一个栈指针,指向我们模拟的内存上的位置。
接着按照 wiki 的定义,我们把 BF 的八个操作符一一实现。
在执行加法和减法操作时,我们需要模拟无符号 8 位会溢出的情况。
执行 BF 代码
我们可以以如下形式执行我们的 BF 代码:
node index.mjs ./res/hello_world.bfHello World
++++++++++[>+++++++>++++++++++>+++>+<<<<-]>++.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.------.--------.>+.>.
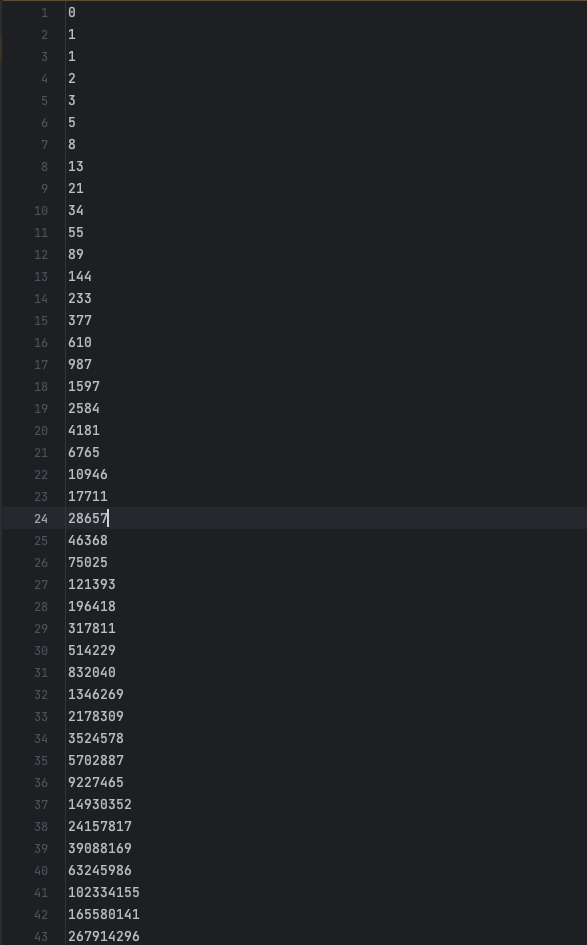
斐波那契数列
可以输出到文件而不是控制台方便查看执行结果:
node index.mjs ./res/fib.bf>++++++++++>+>+[
[+++++[>++++++++<-]>.<++++++[>--------<-]+<<<]>.>>[
[-]<[>+<-]>>[<<+>+>-]<[>+<-[>+<-[>+<-[>+<-[>+<-[>+<-
[>+<-[>+<-[>+<-[>[-]>+>+<<<-[>+<-]]]]]]]]]]]+>>>
]<<<
]
谢尔宾斯基三角形
[ This program prints Sierpinski triangle on 80-column display. ]
>
+ +
+ +
[ < + +
+ +
+ + + +
> - ] >
+ + + + + + + +
[ >
+ + + +
< - ] >
> + + > > > + >
> > + <
< < < < < < < <
< [ - [ - > + <
] > [ - < + > > > . < < ] > > >
[ [
- > + +
+ + + +
+ + [ > + + + +
< - ] >
. < < [ - > + <
] + > [ - > + +
+ + + + + + + + < < + > ] > . [
- ] > ]
] + < < < [ - [
- > + < ] + > [
- < + > > > - [ - > + < ] + + >
[ - < - > ] < <
< ] < < < < ] + + + + + + + + +
+ . + + + . [ - ] < ] + + + + +
* * * * * M a d e * B y : * N Y Y R I K K I * 2 0 0 2 * * * * *
代码居然可以和执行结果长的差不多。
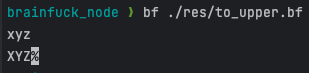
小写转大写
,----------[----------------------.,----------]
尝试解读 BF 代码
其他代码逻辑过于复杂,小写转大写代码量少,相对好解释一些。
首先遇到 ,,等待用户控制台输入。
不断的执行减法,首次遇到 [ 会跳过,因为减法次数不足以其位 0,到达跳转的条件
遇到 . 执行输出,此时已经执行了减法 32 次,刚好能把大写字符转小写。
接着又读取输入,又不断地做减法,知道最后遇到 ], 一般情况它又会跳到上一个 [ 处,特别的遇到回车符时,它的码是 10,执行 10 次减法后遇到 ] 程序便会终止。
总结
BF 八个简单的操作居然也能足够执行复杂的代码。
写一段 BF 代码比起写 BF 的解释器难多了。😂